前言
Cartopy 可以通过 feature 模块向地图添加国界 BORDER 和省界 STATES,因其底层采用的 Natural Earth 地图数据并不符合我国的政治主张,所以我们经常需要自备 shapefile 文件来画中国省界,以下面的代码为例
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.io.shapereader as shpreader
extents = [70, 140, 0, 60]
crs = ccrs.PlateCarree()
fig = plt.figure()
ax = fig.add_subplot(111, projection=crs)
ax.set_extent(extents, crs)
filepath = './data/bou2_4/bou2_4p.shp'
reader = shpreader.Reader(filepath)
geoms = reader.geometries()
ax.add_geometries(geoms, crs, lw=0.5, fc='none')
reader.close()
plt.show()
图就不放了,这段代码足以应付大部分需要画省界的情况。然而我在无脑粘贴代码的过程中逐渐产生了疑惑:为什么 shapefile 会由三个文件组成?省界是以何种形式存储在文件中?Cartopy 和 Matplotlib 又是怎样将省界画出来的?调查一番源码后总结出了这段代码底层实现的流程:
- 利用 PyShp 包读取 shapefile 文件中的每个形状。
- 利用 Shapely 包将形状转换为几何对象。
- 利用 Cartopy 包将几何对象投影到地图所在的坐标系上。
- 用投影后的坐标构造 Matplotlib 的 Path 对象,最后画在地图上。
本文的目的即是从头到尾解说一下这段流程,希望加深对 shapefile 格式,Matplotlib 和 Cartopy 包的理解。令人意外的是,随着探索的不断深入,我发现自己自然而然地学会了如何实现省份填色、省份合并,地图白化等,以前看起来十分困难的操作。本文也会一并介绍这些应用。
Shapefile 简介
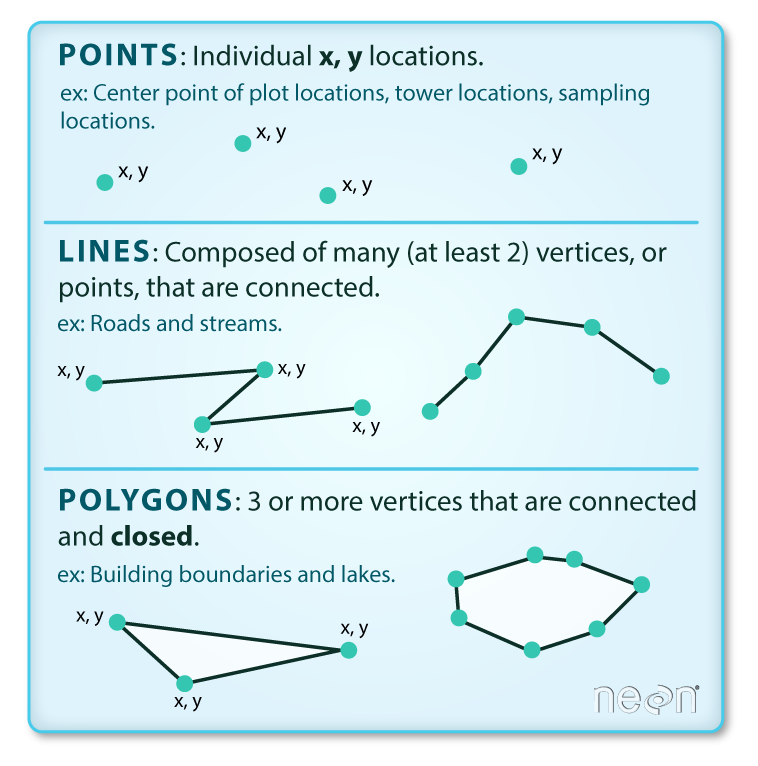
首先要解答的问题是:shapefile 是什么,里面装的什么东西,并且是怎么摆放的。Shapefile 是 ESRI 公司为旗下的 GIS 软件设计的一种存储矢量地理特征(feature)的格式。地理特征由形状(shape)和属性(attribute)构成。形状是一个二维平面图形,可以概括为点(point)、线(line)和面(area)三种,一对 x 和 y 的坐标值构成点,多个点按顺序相连构成线,若一条线能首尾相连绕出一个多边形则构成面,如下图所示(引自 Vector 00: Open and Plot Shapefiles in R)
一个形状绑定一条属性,属性由若干个字段(field)组成,每个字段含有一个值(字符串、数字等)。特征的例子包括:一个气象站点的位置需要用点来表示,对应的属性字段可以是站点的名称和编号;一条河需要用线来表示,对应的属性字段可以是河流的名称和长度;一个省需要用面来表示,对应的属性字段可以是省名、行政区号、周长和面积。一系列特征可以按顺序摆放在 shapefile 文件中,并且要求单个文件中所有特征的形状类型必须相同。于是乎,一个 shapefile 文件可以表示全国所有气象站点的位置,或者一片水系中所有河流的位置,抑或是全国省份的形状等。
Shapefile 的特殊之处在于,一个完整的 shapefile 文件实际上是由同目录下一系列同名但扩展名不同的子文件组成的,其中必须有的三个是:
.shp:存储形状的二进制文件。其中每个形状占据的字节数是可变的。.shx:存储.shp中每个形状从第几个字节开始的二进制文件。用于加快对.shp文件的索引操作。.dbf:存储属性的 dBASE IV 格式文件。每条属性与.shp中的每个形状一一对应。
可选的另有:
.prj:WKT 格式的坐标系信息。只有数行的文本文件。.cpg:存有.dbf中字符编码格式的文本文件。- ……
其实可选的子文件还有很多,但因为并不常见所以不再细述,详见 维基。缺少 .prj 文件时,GIS 软件通常会将 .shp 中形状的坐标解读为 EPSG:4326(WGS84)坐标系中的经纬度。这解释了为什么网上下载到的 shapefile 文件通常只由三个文件组成。
接下来着重介绍 .shp 和 .dbf 中的内容。.shp 中只含两种数据类型:32-bit 整数和 64-bit 双精度浮点数,整数主要用来表示序号和下标之类的量,而浮点数主要用来表示形状的坐标值,并且不允许出现无限(infinity)和缺测(NaN)的浮点数。.shp 的结构组织如下图所示
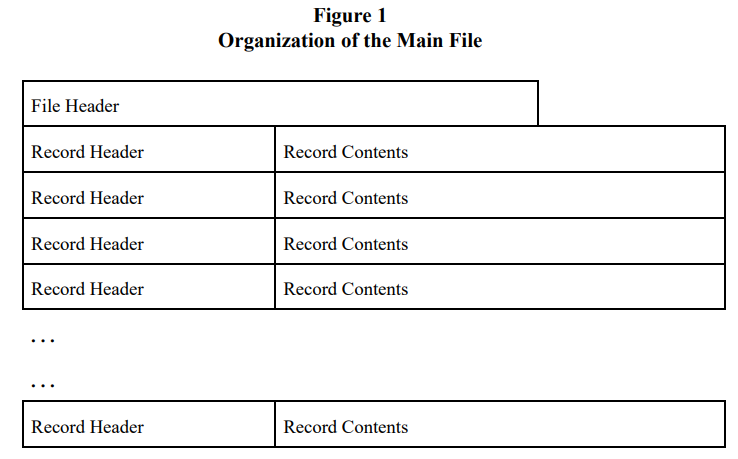
.shp 文件开头前 100 个字节用来存放文件头信息(file header),后面跟着一条又一条的记录(record),每条记录又由记录头信息(record header)和记录内容(record content)组成。文件头信息中比较重要的是形状类型(shape type)和边界框(bounding box)。前文虽然说形状分为点、线、面三种,但实际上可以细分为 14 种,如下表所示
| Value | Shape Type |
|---|---|
| 0 | Null Shape |
| 1 | Point |
| 3 | PolyLine |
| 5 | Polygon |
| 8 | MultiPoint |
| 11 | PointZ |
| 13 | PolyLineZ |
| 15 | PolygonZ |
| 18 | MultiPointZ |
| 21 | PointM |
| 23 | PolyLineM |
| 25 | PolygonM |
| 28 | MultiPointM |
| 31 | MultiPatch |
文件头信息中存储的是形状类型对应的整数代码。虽然类型看起来很多,但一般只会用到 Point、MultiPoint、PolyLine 和 Polygon 这四种,从名字上就能看出直接对应于点、线、面。其它类型的话,Null Shape 表示一个占位的空形状,没有坐标值;带有 M 后缀的类型表示除了坐标值 X 和 Y 以外,还会存储一个测量值(measurement)M,并且这个值允许缺测;带有 Z 后缀的类型在 X、Y 和 M 的基础上又加入了垂直方向上的坐标 Z;MultiPatch 类型甚至能表示建筑物那样的立体图形。边界框定义为能恰好框住文件中所有形状的方框,以 Xmin、Ymin、Xmax 和 Ymax 的形式存储。
记录头信息存有每条记录的编号(从 1 开始)和记录内容的长度,一般用不上。重点还是在于记录内容,因为对地理特征来说最重要的形状特征就存储在记录内容里。首先,下图是 Point 的记录内容
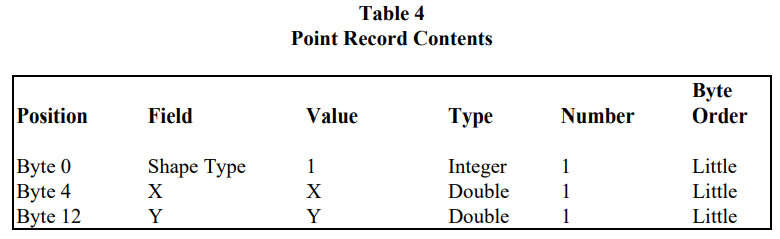
记录中存有三个数值:形状类型的代码、坐标值 X 和 Y。之前说过文件中要求所有形状的类型是相同的,所以这里的代码与文件头信息中的一样都为 1。在缺少 .prj 文件的情况下,X 和 Y 通常用来表示经度和纬度。然后是 MultiPoint 的记录内容
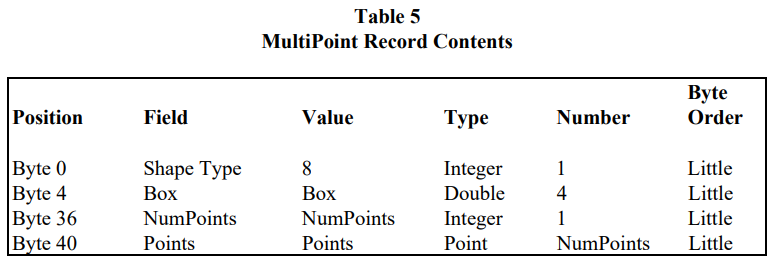
MultiPoint 顾名思义,即许多 Point 的组合,一条 MultiPoint 的记录表示一簇点。记录内容里的 Box 即刚好包住这些点的边界框,由四个浮点数组成所以占 32 个字节;NumPoints 表示一共有几个点;Points 即所有点的坐标,以 [X1, Y1, X2, Y2, X3, Y3, ...] 的形式排列。接着是代表线的形状 PolyLine
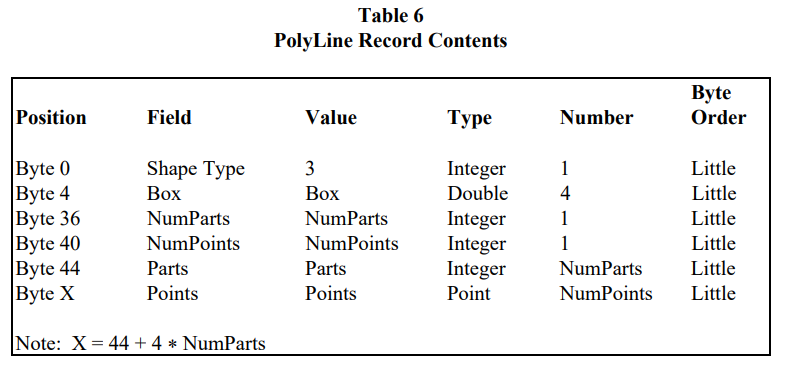
PolyLine 顾名思义是折线,一条折线由至少两个点依次相连而成。但实际上,一条 PolyLine 记录可以表示数条相互独立的折线,每条线称作一个片段(part),片段间可以相交,片段数由 NumParts 描述。NumPoints 表示这些折线的点数之和,Points 是所有点的坐标。为了区分出 Points 中的点都属于哪一片段,又引入了 Parts 数组,标识出每个片段的第一个点对应于 Points 中的第几个点(从 0 开始计数)。举个例子,片段一由两个点组成,片段二由三个点组成,那么片段一满足 Parts[0] = 0,片段二满足 Parts[1] = 2,片段三满足 Parts[2] = 5。最后是最复杂的代表面的 Polygon
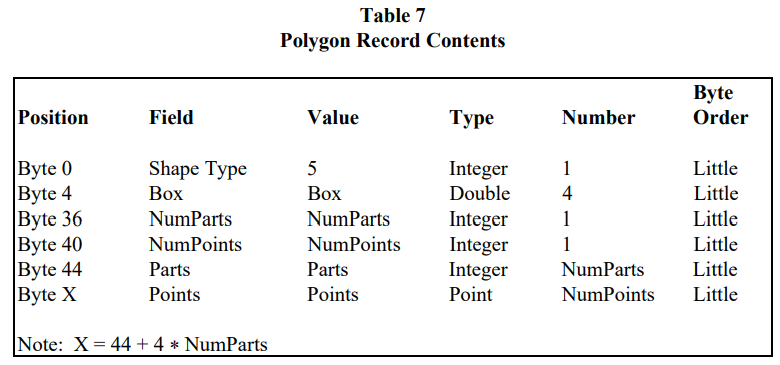
Polygon 顾名思义是多边形,一个多边形由一个环(ring)绕成。所谓环即首尾闭合的折线,要求折线的第一个点与最后一个点是相同的,所以环至少由四个点组成,还要求点与点之间的线段不能发生交叉。然而,多边形是可以有洞的,以甜甜圈为例,外部的圆环与内部的圆环共同绕出了甜甜圈的区域,所以一个多边形可以由一个外环和多个内环(多个洞)组成。为了区分外环内环,人为规定外环沿顺时针方向绕行,内环沿逆时针方向绕行。跟 PolyLine 类似的是,一条 Polygon 记录也可以含有复数个多边形,所以 Polygon 同样存在片段的概念,不过一个片段对应一个环,而非一个片段对应一个独立的多边形。
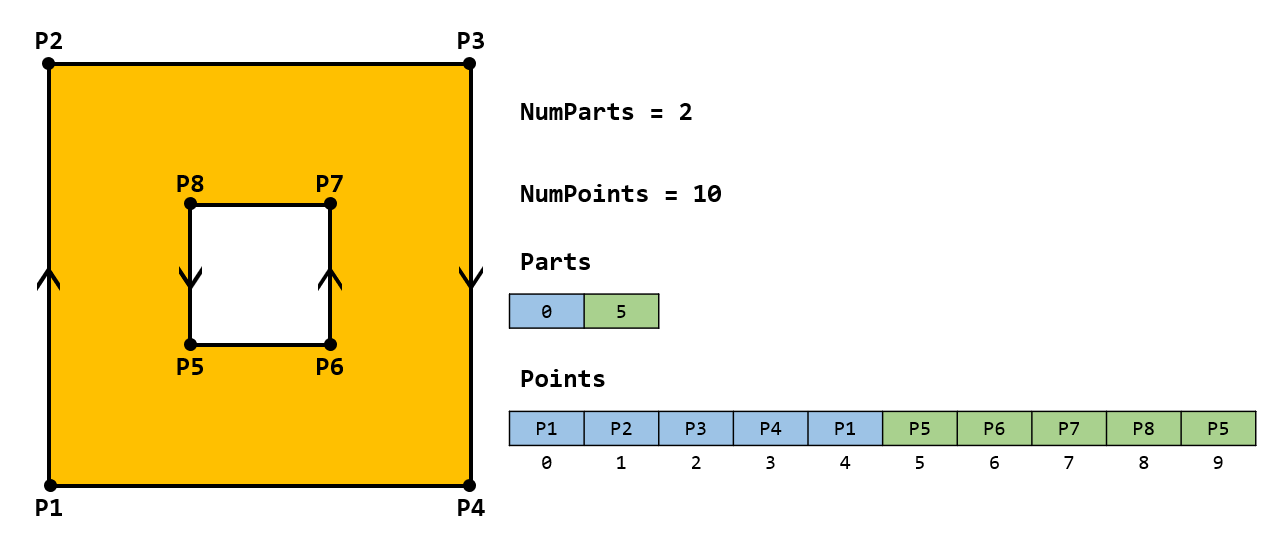
NumParts 即环的个数,NumPoints 是所有环的点数,Points 是依次排列的所有环的坐标,Parts 则标识每个环的第一个点对应于 Points 中的第几个点。值得注意的是,shapefile 并不关心环的顺序,你可以把所有外环的坐标排列在一起,再把所有内环的坐标坐标排列在一起,某种意义上来说 shapefile 只记录有没有洞,而并不关心洞到底开在哪个多边形上。下面这个带洞正方形的例子应该能形象说明 Polygon 的记录内容
顺带一提,因为 MutliPoint、PolyLine 和 Polygon 的记录内容可以含有任意个点,所以记录的长度是不定的。.shx 文件的意义便是通过存储这些记录的起始点相对于文件开头的字节偏移量,帮助 GIS 软件快速定位 .shp 中每条记录的位置。
介绍完 .shp,接下来介绍存储属性的 .dbf。.dbf 基于 dBASE IV,是一种互联网早期的数据库格式,这里不打算细讲其规范(我也偷懒没看),只是简单演示一下如何快速查看其内容。以 bou2_4p.dbf 为例, 据说这是国家地理信息系统很久以前公开发布的文件,如今已无官方下载渠道,但可以在网上简单下载到,例如在 GitHub 上一搜就是一把。bou2_4p 中 bou 表示边界(boundary),数字 1 ~ 4 代表国家、省、市、县的四级行政划分,这里的 2 就表示省界,4 表示比例为 400 万分之一,p 猜测是多边形的意思(参考 中国地图GIS的官方数据(shp文件))。.dbf 文件直接拖入 Excel 便能打开,内容如下图所示
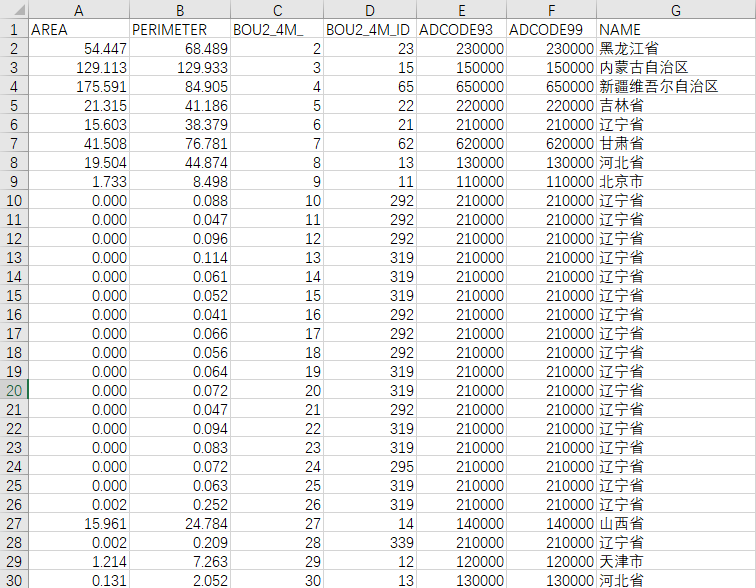
这样看来,所谓 .dbf 不过就是一张二维表格而已。图中 7 列代表 7 个字段,最后两列较为重要:行政区划代码(adcode)和对应的省份名。每条记录对应 .shp 中的一个形状,图中辽宁省的记录出现了十几次,是因为辽宁省含有许多海岛,每个海岛作为单独的一个形状被记录到了 .shp 和 .dbf 中。继续拖动鼠标滚轮会发现沿海省份都是这个样子。之前提到过,一条 Polygon 记录中可以存储复数个多边形,所以也有些 shapefile 会把本土和海岛合并成单条记录。继续查看表格会看到香港特别行政区上面有一条区划代码为 0,名称空着的记录,在 QGIS 中打开后发现原来这是表示香港行政区划的记录,所以多边形覆盖到了海面上,如下图所示
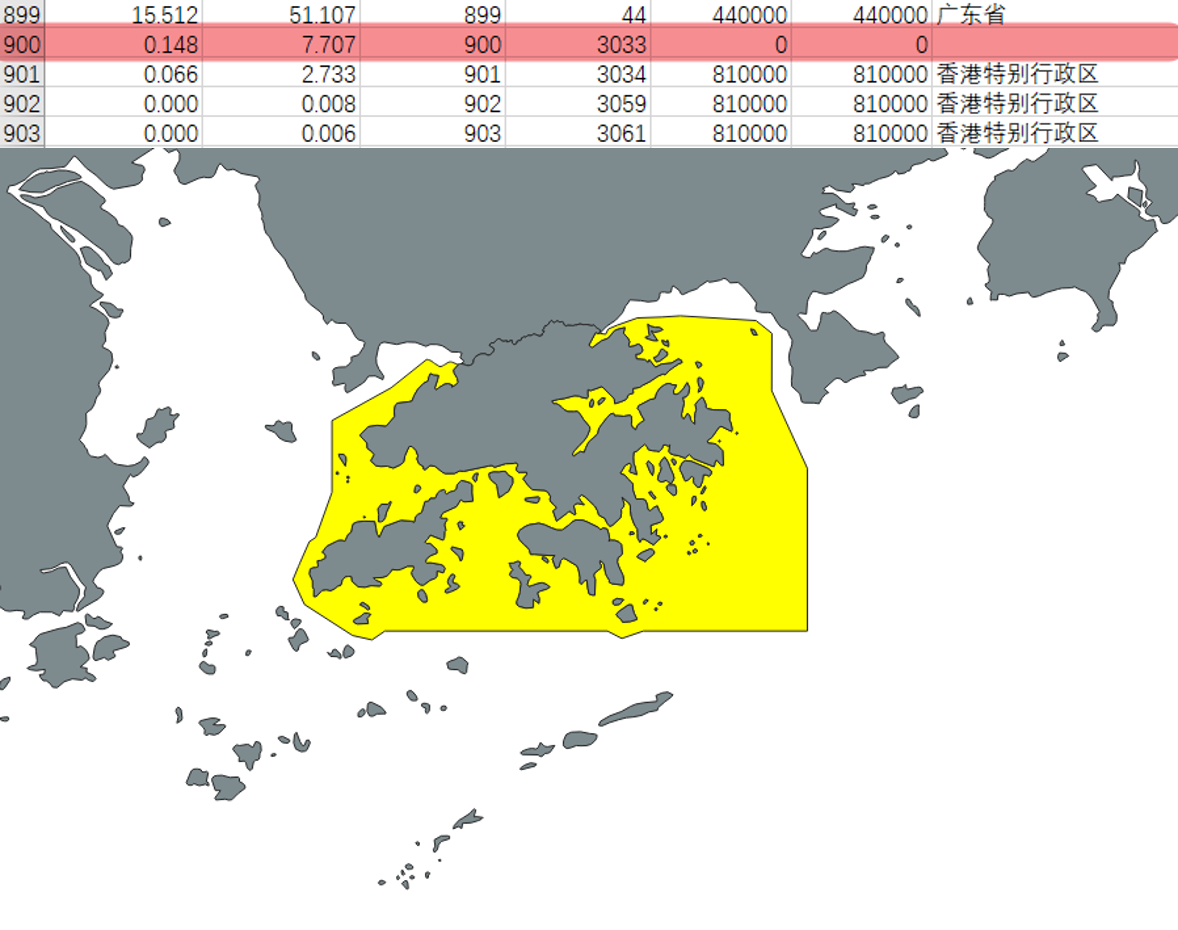
把表格看完后你应该会发现,这里面居然没有澳门特别行政区(820000)。澳门回归是在 1999 年 12 月 20 日,而表中区划代码的字段名 ADCODE99 中刚好有一个 99,让人不禁怀疑这个 shapefile 怕不是用的 99 年初的数据。总之,提前用 Excel 查看一下 .dbf 中的内容,有助于我们理解 shapefile 中存储的内容,便于之后进行更复杂的操作。
最后提一下 shapefile 作为一种地理矢量特征存储格式的优缺点:
- 优点:文件结构简单,读取后画图速度快,应用非常广泛。
- 缺点:不含几何拓扑信息,子文件太多,dBASE 格式限制较多。
本节的内容基本摘自 ESRI 关于 shapefile 的 技术文档,非常推荐想深入了解 shapefile 格式的同学读读这个文档。dBASE 格式的规范见 Xbase File Format Description。
用 PyShp 读写 shapefile
前面属于是纸上谈兵环节,本节就来用 Python 实际操作一下 shapefile。目前主流的能读写 shapefile 的包有四个:PyShp、GDAL、Fiona 和 GeoPandas。其中 PyShp 是纯 Python 实现,没有任何依赖;GDAL 中的 OGR 能够进行矢量数据的 IO 操作,因为底层是 C++ 所以速度更快;Fiona 对 OGR 的 API 做了 Python 风格的封装;而 GeoPandas 又对 Fiona 进行了封装。因为 GDAL 太难装了,并且 Cartopy 也默认使用 PyShp,所以这里基于 PyShp 进行演示,版本为 2.3.0。
PyShp 在程序中的名字就叫 shapefile,用 Reader 类表示文件,用 Shape 类表示形状,用 Record 类表示属性,用 ShapeRecord 类表示同时含有形状和属性的一条记录。下面以 bou2_4p.shp 文件为例
import shapefile
# 文件名可以不加后缀.
# 默认用UTF-8解码属性, 而bou2_4p的编码是GBK.
reader = shapefile.Reader('bou2_4p', encoding='gbk')
# 打印文件头信息.
print(reader.numRecords, reader.numShapes)
print(reader.shapeType, reader.shapeTypeName)
print(reader.bbox)
输出为
925 925
5 POLYGON
[73.44696044921875, 6.318641185760498, 135.08583068847656, 53.557926177978516]
即该文件含 925 条多边形(类型代码为 5)的记录,边界框围绕中国。
读取形状
# 读取第一个形状.
shape = reader.shape(0)
# 获取含所有形状的序列.
shapes = reader.shapes()
shape = shapes[0]
# 迭代器版本的shapes.
for shape in reader.iterShapes():
pass
# 打印形状的头信息.
print(shape.oid)
print(shape.bbox)
print(shape.shapeType, shape.shapeTypeName)
# 打印形状内容.
print(shape.parts)
print(shape.points)
输出为
924
[114.2989273071289, 22.175479888916016, 114.30238342285156, 22.17897605895996]
5 POLYGON
[0]
[(114.2989273071289, 22.17812156677246),
(114.3006362915039, 22.17891502380371),
(114.30207061767578, 22.17897605895996),
(114.30238342285156, 22.178001403808594),
(114.30198669433594, 22.176328659057617),
(114.3009033203125, 22.175479888916016),
(114.2995376586914, 22.176170349121094),
(114.2990493774414, 22.177350997924805),
(114.2989273071289, 22.17812156677246)]
oid 为 924 即最后一个形状。parts 为 [0] 表示这个多边形仅由一个环组成。points 是 (x, y) 点对构成的列表,可以看到起点和终点是同一个点,并且绕行方向为顺时针,说明是外环。
读取属性的方法类似
# 读取第一条属性.
record = reader.record(0)
# 获取含所有属性的序列.
records = reader.records()
record = records[0]
# 迭代器版本的records.
for record in reader.iterRecords():
pass
# 打印属性字段和数值.
print(reader.fields)
print(record.as_dict())
输出为
[('DeletionFlag', 'C', 1, 0),
['AREA', 'N', 12, 3],
['PERIMETER', 'N', 12, 3],
['BOU2_4M_', 'N', 11, 0],
['BOU2_4M_ID', 'N', 11, 0],
['ADCODE93', 'N', 6, 0],
['ADCODE99', 'N', 6, 0],
['NAME', 'C', 34, 0]]
{'AREA': 0.0,
'PERIMETER': 0.011,
'BOU2_4M_': 926,
'BOU2_4M_ID': 3115,
'ADCODE93': 810000,
'ADCODE99': 810000,
'NAME': '香港特别行政区'}
为了解读输出内容,需要了解一下 PyShp 中字段的表示。字段由四个元素的序列描述,元素依次为:
- Field name:字符串表示的字段名。
- Field type:字段类型,可以细分为:
'C':字符型。'N':数值型,因为实际上保存为字符所以整数或浮点数都行。'F':浮点型,同'N'。'L':逻辑型,用来表示真假值。'D':日期型。'M':备忘录型,在 shapefile 中用不到。
- Field length:表示字段数值的字符的长度。
- Decimal length:
'N'或'F'型中小数部分的位数。
所以行政区划代码的字段表示为 ['ADCODE99', 'N', 6, 0],即一个六位整数;而省名的字段表示为 ['NAME', 'C', 34, 0],即最长 34 个字符的字符串。然而测试后发现 field length 实际上表示字节数,对于 GBK 或 UTF-8 编码来说并不等同于字符数。值得注意的是,字段中有一个奇怪的 DeletionFlag,表示一条记录已经被删除但还未从文件中移除。这个字段几乎没有用处,只是在创建 shapefile 时会自动生成,所以我们直接忽略即可。具体某个字段的值可以以属性或字典的风格来提取:record['NAME'] 和 record.NAME。而上面的代码中则是通过 record.as_dict() 以字典的形式直接显示出所有字段的值。
除了 Shape 和 Record,还可以通过 shapeRecord 同时获取形状和属性,同样有 shapeRecord、shapeRecords 和 iterShapeRecords 三种方法。下面是一个筛选河北省记录的例子
shapeRecs = []
for shapeRec in reader.iterShapeRecords():
if shapeRec.record['NAME'] == '河北省':
shapeRecs.append(shapeRec)
print(len(shapeRecs))
输出为 9,即 bou2_4p 中有 9 条河北省相关的记录。
接着简单演示一下如何用 PyShp 创建新文件
import numpy as np
def make_circle(xc, yc, r, npt=100):
'''创建一个逆时针绕行的圆.'''
theta = np.linspace(0, 2 * np.pi, npt)
x = r * np.cos(theta) + xc
y = r * np.sin(theta) + yc
xy = np.column_stack((x, y))
return xy
# 需要将数组转为列表.
ring = make_circle(1, 1, 1).tolist()[::-1]
hole = make_circle(1, 1, 0.5).tolist()
# 如果首尾不相连, PyShp会在末尾自动补上起点.
rect = [[3, 0], [3, 2], [5, 2], [5, 0], [3, 0]]
# 采用默认的UTF-8编码.
writer = shapefile.Writer('donut')
# 仅设置名称字段, 并且采用默认的字段长度.
writer.field('name', 'C')
# 写入甜甜圈形状.
writer.poly([ring, hole])
writer.record('donut')
# 写入方框形状.
writer.poly([rect])
writer.record('rectangle')
writer.close()
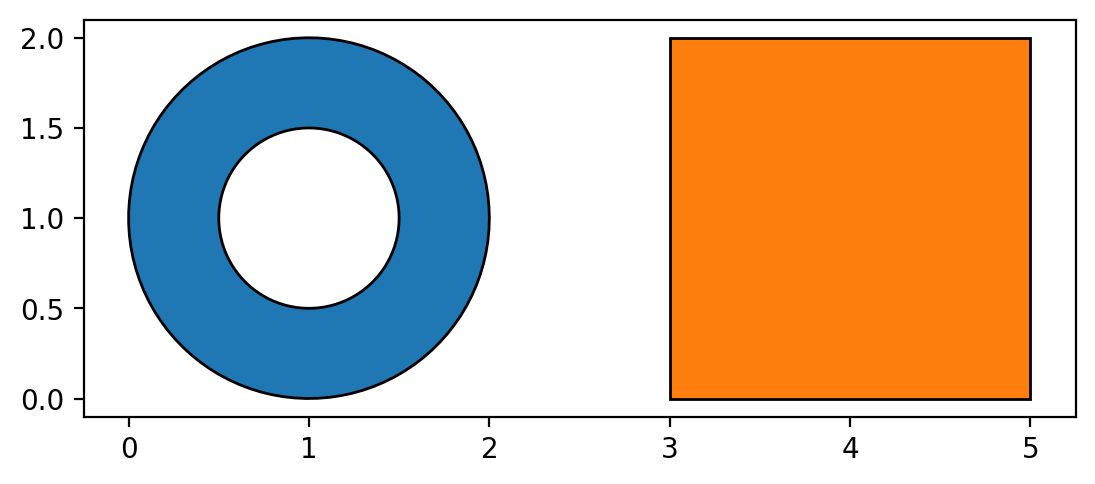
PyShp 用 Writer 类创建文件对象,用 field 方法逐个设置字段,参数就是前文提到的四个元素。再用 null、point、multipoint、line 和 poly 等方法写入形状,同时每个形状必须对应一条 record 方法写入的记录。结果是生成了 donut.shp、donut.shx 和 donut.dbf 三个文件,含有甜甜圈和矩形两个记录。用 GIS 软件打开便能直接验证新建的文件是否正确,不过下节将会介绍如何用 Matplotlib 来绘制其形状。
本节只是一个简单的介绍,PyShp 相关的更多操作请参考其 主页。
用 Matplotlib 绘制 shapefile
对于 Point 类型的 shapefile,可以有
# 这里的x和y是标量.
for shape in reader.iterShapes():
x, y = shape.points[0]
ax.scatter(x, y)
对于 MultiPoint 类型的 shapefile,可以有
# 这里的x和y是数组.
for shape in reader.iterShapes():
x, y = zip(*shape.points)
ax.scatter(x, y)
对于 PolyLine 类型的 shapefile,需要根据 parts 里存储的下标,将 points 划分为相互独立的折线
for shape in reader.iterShapes():
for i, start in enumerate(shape.parts):
try:
end = shape.parts[i + 1]
except IndexError:
end = None
x, y = zip(*shape.points[start:end])
ax.plot(x, y)
对于 Polygon 类型,固然可以用 ax.plot 方法用线表示多边形的环,但如果想实现颜色填充的效果的话,需要引入 matplotlib.path 模块中的 Path 类。Path 直译为路径,由一系列顶点(vertices)和控制顶点处连线的代码(code)构成。Path 本身并非 Aritist 对象,但将 Path 转为 PathPatch 或 PathCollection 对象后便可以画在 Axes 上,路径连线的粗细和颜色,路径环绕出的区域内的填色等要素都可以进行设置。Matplotlib 中用来画方框、椭圆、多边形等图形的 Patch 类便是基于 Path 实现。有人可能会问,那为什么不直接使用 matplotlib.patches.Polygon 来画 shapefile 呢?这是因为这个类不能区分出多边形中的洞,而底层的 Path 却可以。
下面是 Path 相关的控制代码,以类属性的形式引用
| Code | Vertices | Description |
|---|---|---|
| MOVETO | 1 | 结束上一条折线,提起画笔从当前顶点开始画。 |
| LINETO | 1 | 从上一个顶点画直线到当前顶点。 |
| STOP | 1 (ignored) | 忽略当前顶点,连线停留在上一个顶点。 |
| CLOSEPOLY | 1 (ignored) | 忽略当前顶点,从上一个顶点画直线到当前折线的起点以实现闭合。 |
除此之外还有指定二次贝塞尔曲线的 CURVE3 和三次贝塞尔曲线的 CURVE4,不过因为和本文的主题无关,所以这里省略掉了。类似 shapefile 的 PolyLine,一条路径可以由多条折线构成,只要用控制代码标识出折线的分组即可。当折线首尾相连成环,或者每条折线的最后一个顶点都设置成 CLOSEPOLY 时,即可用路径来描述多边形。Shapefile 中要求多边形的外环沿顺时针方向,内环沿逆时针方向,而路径只需要内环和外环的绕行方向不同即可(参考 Matplotlib 的甜甜圈示例)。以一个镂空的正方形为例,路径需要描述两段方向相反的环
from matplotlib.path import Path
verts = [
(0, 0), (0, 3), (3, 3), (3, 0), (0, 0), # 顺时针外环.
(1, 1), (2, 1), (2, 2), (1, 2), (1, 1) # 逆时针内环.
]
codes = [
Path.MOVETO, Path.LINETO, Path.LINETO, Path.LINETO, Path.CLOSEPOLY,
Path.MOVETO, Path.LINETO, Path.LINETO, Path.LINETO, Path.CLOSEPOLY
]
path = Path(verts, codes)
最后以上一节的 donut.shp 文件为例
import shapefile
import matplotlib.pyplot as plt
import matplotlib.path as mpath
import matplotlib.patches as mpatches
def ring_codes(n):
'''为长度为n的环生成codes.'''
codes = [mpath.Path.LINETO] * n
codes[0] = mpath.Path.MOVETO
codes[-1] = mpath.Path.CLOSEPOLY
return codes
def polygon_to_path(shape):
'''将Polygon类型的Shape转换为Path.'''
if shape.shapeTypeName != 'POLYGON':
raise ValueError('输入不是多边形')
verts = shape.points
codes = []
for i, start in enumerate(shape.parts):
try:
end = shape.parts[i + 1]
except IndexError:
end = len(verts)
codes += ring_codes(end - start)
path = mpath.Path(verts, codes)
return path
# 将Shape全部转换为Path.
paths = []
with shapefile.Reader('donut') as reader:
for shape in reader.iterShapes():
paths.append(polygon_to_path(shape))
# 将Path转为Patch后画在Axes上.
fig, ax = plt.subplots()
for i, path in enumerate(paths):
color = plt.cm.tab10(i)
patch = mpatches.PathPatch(path, fc=color, ec='k', lw=1)
ax.add_patch(patch)
# 将Axes的横纵坐标比例设为1:1
ax.set_aspect('equal')
# 添加patch时Axes不会自动调节显示范围.
ax.autoscale_view()
plt.show()
同理 bou2_4p 也能用同样的方法画出。可能有人会问,既然能直接用 Matplotlib 画,为什么还需要 Cartopy 呢?理由是 Cartopy 提供的方法能简化读取和绘制 shapefile 的过程,不需要像上面那样对 points 手动进行分割,并且能自动处理投影坐标系间的变换。不过为此需要先引入 GeoJSON 格式和 Shapely 包。
GeoJSON 简介
Shapely 包提供了对几何对象进行计算的功能,例如求两条线段的交点、判断点是否在多边形内、合并两个多边形得到一个大多边形,以及求两个多边形重叠的部分等。所以将 PyShp 包读取到的 shape 对象转为 Shapely 包中的几何对象(geometry),有助于进行后续的处理。但在转换过程中需要以 GeoJSON 作为中间格式,所以这一节先简单介绍一下 GeoJSON。并且 GeoJSON 在 WebGIS 领域(例如高德地图那种)非常流行,以后很可能会在工作中遇到,多了解一点也没有坏处。下文基于 2015 年的 RFC 7946 规范。
GeoJSON 也是一种常见的存储地理空间数据的格式,通过一系列格式上的约定得以用 JSON 表现特征、形状和属性信息。GeoJSON 中的对象相当于 Python 的字典,有一个名为 type 的键,其字符串值表示对象类型。特征在 GeoJSON 中以 Feature 对象表示,一系列特征排列在数组中便构成了 FeatureCollection 对象。Feature 中含有的 geometry 对应于几何(形状)对象,properties 以字典形式存储属性字段及其数值。
GeoJSON 定义的几何对象与 shapefile 相似,点、线、面分别用 Point、LineString 和 Polygon 对象表示。几何对象含有一个 coordinates 数组,存放所有点的坐标值,这与 shapefile 形状的 Points 数组完全一致。GeoJSON 明确使用 MultiPoint、MultiLineString 和 MultiPolygon 表示多个点、多条折线和多个多边形,对应的 coordinates 数组中嵌套存放多个形状的坐标值。因此 GeoJSON 不需要 shapefile 中表示下标的 Parts 数组,处理起来更简单。另外 GeoJSON 还提供一种 GeometryCollection 几何对象,可以存放不同类型的几何对象,但用的要相对少些。
首尾相连的折线称作线性环(linear ring),Polygon 便是由一个或多个线性环组成,但线性环本身并不算正式定义的几何对象。GeoJSON 中的多边形同样有内外环之分,区别在于 shapefile 要求外环顺时针绕行,内环逆时针绕行,且 Points 中内外环的摆放顺序随意;而 GeoJSON 中要求外环逆时针绕行,内环顺时针绕行,且 coordiantes 中第一个子数组是外环的坐标对序列,后面的子数组才对应于内环。换句话说,GeoJSON 会记录洞和多边形的归属信息,这有助于我们后面使用 Shapely 创建多边形对象。不过 GeoJSON 为了保证对老规范的兼容性,允许内外环的绕行方向不合法,毕竟还可以利用 coordinates 中成员的位置来确定。下面是各种几何对象的文本表示
// 点(0, 0).
{
"type": "Point",
"coordinates": [0.0, 0.0]
}
// 点(0, 0)和(1, 1).
{
"type": "MultiPoint",
"coordinates": [
[0.0, 0.0],
[1.0, 1.0]
]
}
// 点(0, 0)到(1, 1)的连线.
{
"type": "LineString",
"coordinates": [
[0.0, 0.0],
[1.0, 1.0]
]
}
// 加上(2, 2)到(3, 3)的连线.
{
"type": "MultiLineString",
"coordinates": [
[
[0.0, 0.0],
[1.0, 1.0]
],
[
[2.0, 2.0],
[3.0, 3.0]
]
]
}
// 带洞的正方形.
{
"type": "Polygon",
"coordinates": [
[
[0.0, 0.0],
[3.0, 0.0],
[3.0, 3.0],
[0.0, 3.0],
[0.0, 0.0]
],
[
[1.0, 1.0],
[1.0, 2.0],
[2.0, 2.0],
[2.0, 1.0],
[1.0, 1.0]
]
]
}
// 在右边再加一个正方形.
{
"type": "MultiPolygon",
"coordinates": [
[
[
[0.0, 0.0],
[3.0, 0.0],
[3.0, 3.0],
[0.0, 3.0],
[0.0, 0.0]
],
[
[1.0, 1.0],
[1.0, 2.0],
[2.0, 2.0],
[2.0, 1.0],
[1.0, 1.0]
]
],
[
[
[5.0, 0.0],
[8.0, 0.0],
[8.0, 3.0],
[5.0, 3.0],
[5.0, 0.0]
]
]
]
}
这里再啰嗦点,用表格总结一下 shapefile 和 GeoJSON 的概念对应关系
| shapefile | GeoJSON |
|---|---|
| shape | geometry |
| attributes | properties |
| Points | coordinates |
| Point | Point |
| MultiPoint | MultiPoint |
| PolyLine | LineString or MultiLineString |
| Polygon | Polygon or MultiPolygon |
PyShp 通过 __geo_interface__ 接口实现了 shapefile 到 GeoJSON 的格式转换:
reader.__geo_interface__返回FeatureCollection。shapeRec.__geo_interface__返回Feature。shape.__geo_interface__返回几何对象。
稍微提一下这个接口对于多边形的处理:首先根据绕行方向将所有环分为外环和内环两种,然后为每个内环找到唯一的父亲外环,如果找不到则删除孤儿内环。因为使用的纯 Python 算法较为简单,所以并不能保证转换结果严格正确,甚至还可能转换失败,不过足够一般使用。PyShp 2.2 中还会额外把环的绕行方向颠倒过来,以符合 GeoJSON 新规范的要求,不过这一行为在 2.3 中又取消掉了(见 cartopy issue#2012)。下面将 bou2_4p.shp 文件转为 GeoJSON 格式
import json
with shapefile.Reader('./data/bou2_4/bou2_4p.shp', encoding='gbk') as reader:
geoj = reader.__geo_interface__
# 中文Windows环境下, open默认采用GBK编码.
with open('./data/bou2_4/bou2_4p.json', 'w', encoding='utf-8') as f:
json.dump(geoj, f, indent=4, ensure_ascii=False)
生成的 GeoJSON 文件的结构可以用下图直观展示

图中只展示了北京市 Feature 里的详细内容,并且略去了 coordinates 中的数值。
最后提一下 GeoJSON 相对于 shapefile 的优点:
- 以文本而非二进制形式存储,可读性更强。
- 引入了
MultiLineString和MultiPolygon几何对象,便于程序解析坐标。 - 记录了多边形内外环的从属关系,便于后续用 Shapely 包处理。
- GeoJSON 仅由单个 JSON 文件组成。
用 Shapely 操作多边形
Shapely 是一个基于 GEOS 库的计算几何包,能够对平面直角坐标系中的几何对象进行操作。Shapely 真要细讲的话需要新开一篇文章,这里只能快速展示与主题相关的部分。Shapely 主要实现了以下几种几何对象:Point、LineString、LinearRing 和 Polygon,同时还有 MultiPoint、MultiLineString 和 MultiPolygon。可见与 GeoJSON 的规范高度一致。shapely.geometry.shape 函数能够将 GeoJSON 的几何对象,或者实现了 __geo_interface__ 接口的对象(例如 PyShp 的 shape 对象)自动转换为 Shapely 中的几何对象。依旧以 bou2_4p.shp 文件为例
import shapely.geometry as sgeom
from shapely.ops import unary_union
# 提取出京津冀的形状.
# 其中河北省由多个多边形组成.
hebei = []
with shapefile.Reader('./data/bou2_4/bou2_4p.shp', encoding='gbk') as reader:
for shapeRec in reader.iterShapeRecords():
name = shapeRec.record['NAME']
if name == '北京市':
beijing = sgeom.shape(shapeRec.shape)
elif name == '天津市':
tianjin = sgeom.shape(shapeRec.shape)
elif name == '河北省':
hebei.append(sgeom.shape(shapeRec.shape))
# 含Polygon的列表构造MultiPolygon
hebei = sgeom.MultiPolygon(hebei)
# 合并三个几何对象.
jingjinji = unary_union([beijing, tianjin, hebei])
Polygon 对象由外环 Polygon.exterior 和多个内环 Polygon.interiors 组成,其中 exterior 是 LinearRing 对象,而 interiors 是一系列 LinearRing 构成的序列。环的坐标通过 LinearRing.coords 属性访问,coords 同样也是一种序列,可以通过 list(coords) 或 coords[:] 转换为熟悉的 xy 坐标列表的形式。多个 Polygon 对象可以构造 MultiPolygon 对象,其成员通过 MultiPolygon.geoms 属性访问,环及其坐标的获取则通过 geoms[0].exterior 和 geoms[0].exterior.coords 实现。
因为 bou2_4p.shp 中北京市和天津市都只由单个多边形表示,而河北省由 9 个多边形构成,所以代码中用 MultiPolygon 表示河北省。Polygon.union 或 MultiPolygon.union 方法可以用来合并两个多边形,但运算效率不是很高。所以这里使用更高效的 shapely.ops.unary_union 函数进行合并操作,得到京津冀地区的形状(含海岛)。当然没图说个锤子,下面改写前文的 polygon_to_path 函数,用 Matplotlib 绘制 Shapely 的多边形
def polygon_to_path(polygon):
'''将Polygon或MultiPolygon转为Path.'''
if hasattr(polygon, 'geoms'):
polygons = polygon.geoms
else:
polygons = [polygon]
# 空多边形需要占位.
if polygon.is_empty:
return mpath.Path([(0, 0)])
# 用多边形含有的所有环的顶点构造Path.
vertices, codes = [], []
for polygon in polygons:
for ring in [polygon.exterior] + polygon.interiors[:]:
vertices += ring.coords[:]
codes += ring_codes(len(ring.coords))
path = mpath.Path(vertices, codes)
return path
画图部分为
fig, axes = plt.subplots(1, 2)
# 第一张子图分别画京津冀三地.
for i, geom in enumerate([beijing, tianjin, hebei]):
color = plt.cm.tab10(i)
path = polygon_to_path(geom)
patch = mpatches.PathPatch(path, fc=color, ec='k', lw=1)
axes[0].add_patch(patch)
axes[0].set_title('Before Union')
# 第二张子图画合并后的京津冀.
path = polygon_to_path(jingjinji)
patch = mpatches.PathPatch(path, fc='lightgrey', ec='k', lw=1)
axes[1].add_patch(patch)
axes[1].set_title('After Union')
# 调整比例和显示范围.
for ax in axes:
ax.set_aspect('equal')
ax.autoscale_view()
plt.show()
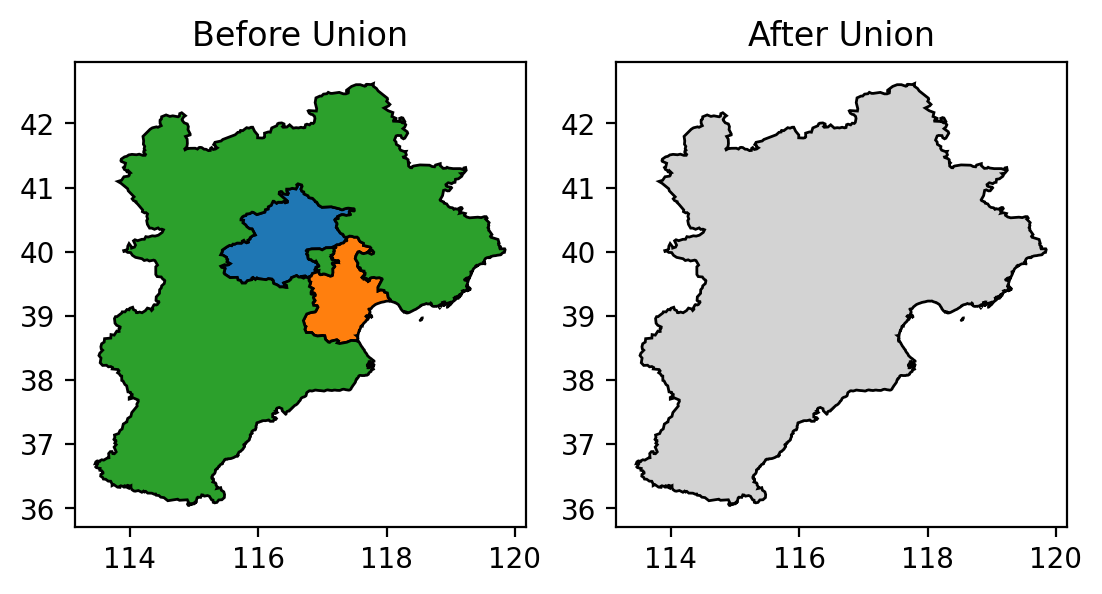
可以看到第二张图中三个地区间的边界在合并后消失了。
上面的演示只是 Shapely 丰富功能中的冰山一角,想了解更多用法请参阅官网的 User Manual。
用 Cartopy 绘制 shapefile
如果把本文的目的,即理解 Cartopy 是怎么画省界的,比作打 Boss 的话,那么前面对各种格式和包的学习就相当于是疯狂练级,现在终于到了能数值碾压 Boss 的阶段。重新回顾一下本文开头的代码(基于 Cartopy 0.20.3),首先是读取 shapefile 文件的部分
import cartopy.io.shapereader as shpreader
filepath = './data/bou2_4/bou2_4p.shp'
reader = shpreader.Reader(filepath)
geoms = reader.geometries()
cartopy.io.shapereader 模块提供了读取 shapefile 的 Reader 类,其定义为
if _HAS_FIONA:
Reader = FionaReader
else:
Reader = BasicReader
即 Python 环境里如果安装了 Fiona 包就以 Fiona 为后端,通过 FionaReader 进行读取;否则以 PyShp 为后端,通过 BasicReader 进行读取。因为 Cartopy 在安装时肯定会依赖 PyShp,所以这里就以 BasicReader 为例继续讲解。其类定义为
class BasicReader:
def __init__(self, filename):
# Validate the filename/shapefile
self._reader = reader = shapefile.Reader(filename)
if reader.shp is None or reader.shx is None or reader.dbf is None:
raise ValueError("Incomplete shapefile definition "
"in '%s'." % filename)
self._fields = self._reader.fields
def close(self):
return self._reader.close()
def __len__(self):
return len(self._reader)
def geometries(self):
'''Return an iterator of shapely geometries from the shapefile.'''
for shape in self._reader.iterShapes():
# Skip the shape that can not be represented as geometry.
if shape.shapeType != shapefile.NULL:
yield sgeom.shape(shape)
def records(self):
'''Return an iterator of :class:`~Record` instances.'''
# Ignore the "DeletionFlag" field which always comes first
fields = self._reader.fields[1:]
for shape_record in self._reader.iterShapeRecords():
attributes = shape_record.record.as_dict()
yield Record(shape_record.shape, attributes, fields)
可以看出 BasicReader 是对 PyShp 的 Reader 类的包装和简化。geometries 方法与 iterShapes 方法类似,都是返回惰性的迭代器,区别在于 Cartopy 返回的是 Shapely 中的几何对象。records 方法与 iterShapeRecords 类似,返回的是同时含有形状和属性的记录。Record.geometry 表示 Shapely 几何对象,Record.attributes 以字典表示属性。不过 BasicReader 的一个问题是,没有选择字符编码的参数,所以若 shapefile 中的属性采用的是非 UTF-8 的编码(例如 GBK)时,调用 records 方法就会报错。解决方法是修改 Cartopy 的源码,添上 encoding 参数。
本节开始不再使用 bou2_4p.shp,而是采用 ChinaAdminDivisonSHP 项目提供的省界文件,数据来源是高德 Web 服务 API 中的行政区域查询。相比 bou2_4p 来说符合最新的行政区划,省界轮廓更加精细,并且一个省仅对应一条记录,即省的形状用 MultiPolygon 表示。另外这一文件用的是 UTF-8 编码,Cartopy 读取时不会有编码问题。下面是 Cartopy 版筛选河北省记录的例子
filepath = './data/ChinaAdminDivisonSHP/2. Province/province'
reader = shpreader.BasicReader(filepath)
for record in reader.records():
if record.attributes['pr_name'] == '河北省':
break
接下来要解说的是这一句
ax.add_geometries(geoms, crs, lw=0.5, fc='none')
add_geometries 顾名思义是往 GeoAxes 上添加几何形状,函数签名为
add_geometries(self, geoms, crs, **kwargs)
geoms 是 Shapely 几何对象的序列,不过事实证明迭代器也行。crs 指定几何对象所处的坐标系,考虑到 shapefile 文件的投影多为等经纬度投影,指定 crs=ccrs.PlateCarree() 即可。kwargs 是传给 matplotlib.collections.PathCollection 的参数,用来指定画路径的效果,例如 facecolor、edgecolor、linewidth 和 alpha 等。PathCollection 的作用是把一系列路径对象聚合成单个 Artist,相比逐个绘制 PathPatch 来说效率更高。add_geometries 的源码涉及多个模块,下面仅展示精简后的核心部分
from matplotlib.collections import PathCollection
import cartopy.feature as cfeature
import cartopy.mpl.patch as cpatch
def add_geometries(ax, geoms, crs, **kwargs):
'''Add the given shapely geometries (in the given crs) to the axes.'''
# 只选取落入地图显示范围中的几何对象进行绘制.
feature = cfeature.ShapelyFeature(geoms, crs, **kwargs)
extent = ax.get_extent(crs)
geoms = feature.intersecting_geometries(extent)
paths = []
for geom in geoms:
# 将几何对象投影到地图坐标系中.
if ax.projection != crs:
geom = ax.projection.project_geometry(geom, crs)
paths.extend(cpatch.geos_to_path(geom))
# 构造Collection对象并绘制.
transform = ax.projection._as_mpl_transform(ax)
c = PathCollection(paths, transform=transform, **kwargs)
ax.add_collection(c)
首先是将几何对象的序列转为 ShapelyFeature 对象,利用其 intersecting_geometries 方法过滤掉没有落入地图显示范围内的几何对象,这样在画图时就能略去看不到的部分,避免浪费时间。然后代表地图投影坐标系统的 ax.projection 有一个 project_geometry 方法,能够将输入的几何对象从 crs 坐标系变换到 ax.projection 坐标系,返回新的几何对象。geos_to_path 函数与前文我们实现的 polygon_to_path 函数功能一样(返回结果略有差别),是把几何对象转为 Matplotlib 的路径对象,以便之后画图。这里 _as_mpl_transform 的作用说实话我没看太懂,看有没有读者能解释一下。最后是构造 PathCollection,并把准备好的 kwargs 画图参数也输入进去,然后添加到 GeoAxes 上。
然而 add_geometries 也存在一些问题:
- 是
GeoAxes专属的方法,普通的Axes没有。 geoms可以是点或线几何,但点画出来看不到,线最好设置fc='none'。geoms中如果有几何对象被过滤掉了,那么上色顺序会跟facecolors或array参数的顺序不符。- 没有返回值,不方便作为
mappable对象传给 colorbar。
为了改进这些问题,下面手工实现一个版本
def add_polygons(ax, polygons, **kwargs):
'''将多边形添加到Axes上. GeoAxes可以通过transform参数指定投影.'''
paths = [polygon_to_path(polygon) for polygon in polygons]
pc = PathCollection(paths, **kwargs)
ax.add_collection(pc)
return pc
函数改名为 add_polygons,强调是专门用来画多边形的。点可以用 ax.scatter 画,线可以用 ax.plot 画,并不是非得用 Path。代码中为了简单去掉了 intersecting_geometries 的功能,甚至还去掉了 project_geometry 的部分,因为我发现在 **kwargs 中传入 transform=crs 便能正确处理投影变换。也正是因为去掉了这两部分,现在 ax 可以是普通的 Axes。最后增加了返回值 pc,方便传给 colorbar。下面利用该函数画省界试试
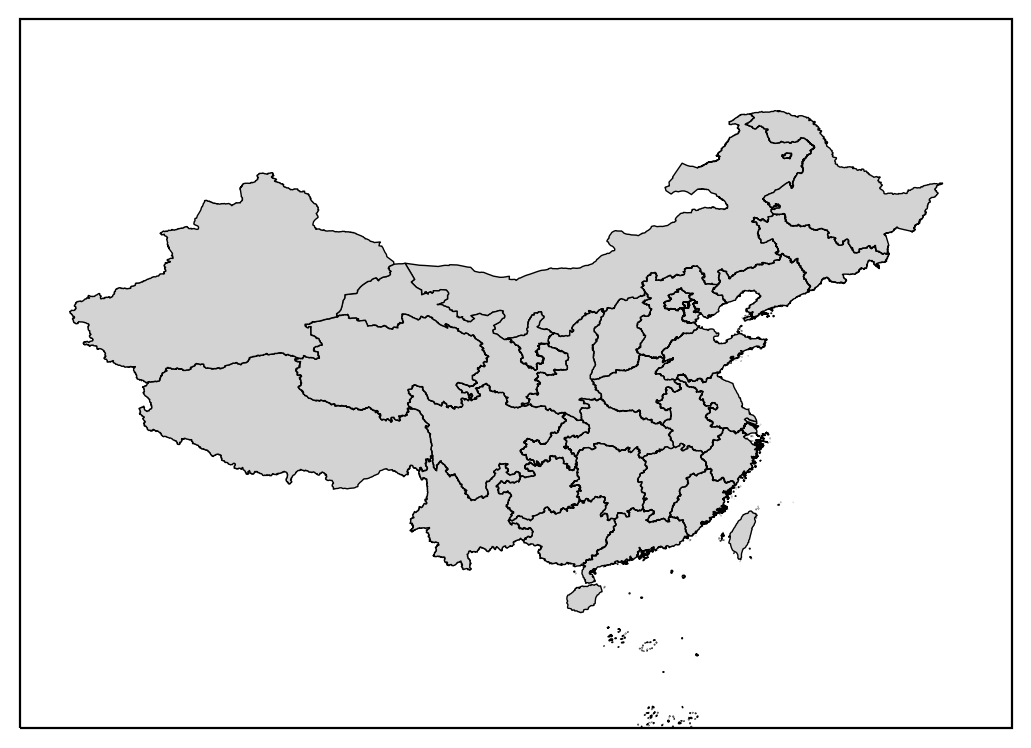
filepath = './data/ChinaAdminDivisonSHP/2. Province/province'
reader = shpreader.BasicReader(filepath)
provinces = reader.geometries()
crs = ccrs.PlateCarree()
fig = plt.figure()
ax = fig.add_subplot(111, projection=crs)
ax.set_extent([70, 140, 10, 60], crs)
add_polygons(
ax, provinces, fc='lightgrey', ec='k', lw=0.5,
transform=crs
)
plt.show()
简单应用
为落入多边形的网格点生成掩膜(mask)数组,之后掩膜数组可以用来将多边形外的数据点设为缺测
from shapely.vectorized import contains
mask = contains(polygon, lon, lat)
data[~mask] = np.nan
最直接的思路当然是为每个网格点构造 Point 对象,然后利用 Polygon.contains(Point) 来判断点是否落入多边形内,但这种方法速度极慢。后来我在看 regionmask 包的源码时发现了矢量化版本的 contains 函数,效率对于日常数据处理来说绰绰有余。另外还可以通过递归分割来优化循环法,可见 Cartopy 系列:利用多边形生成掩膜数组 一文。现成的其它选择还有 regionmask、salem、rasterio 等包([python绘图 |
salem一招解决所有可视化中的掩膜(Mask)问题](https://mp.weixin.qq.com/s?__biz=MzA3MDQ1NDA4Mw==&mid=2247485322&idx=1&sn=25a3a7c9455da919a8e428cd6a099264&chksm=9f3dd9a6a84a50b01e112bb07c718fe041cfde1a539a0f7a4619cd90c62694d8fa45b31c3282&scene=21))。 |
对填色图、风矢量等画图结果进行白化,将多边形轮廓外面的部分设成白色,仅在轮廓内部显示绘图结果
def clip_by_polygon(artist, polygon):
'''利用多边形裁剪画图结果.'''
ax = artist.axes
path = polygon_to_path(polygon)
if hasattr(artist, 'collections'):
for collection in artist.collections:
collection.set_clip_path(path, ax.transData)
else:
artist.set_clip_path(path, ax.transData)
cf = ax.contourf(lon, lat, data, levels=10)
clip_by_polygon(cf, polygon)
显然前面的 contains 函数能通过设置 NaN,在数据层面实现白化效果,缺点是当网格分辨率较粗时,填色图的边缘会出现明显的锯齿感。而利用 Matplotlib 的 Artist.set_clip_path 方法,以一个 Path 或 Patch 对象作为轮廓,裁剪掉 Artist 在轮廓外面的部分,就能在画图层面实现白化效果,观感更为平滑自然,缺点是对数据处理没有什么帮助。网上非常流行的 maskout 包(实际上是一个模块)的原理便是后者(Python完美白化、提高白化效率 等)。而 maskout 的问题在于把 shapefile 文件的读取和白化功能都放在了 shp2clip 函数里,并且假定读者的文件的字段排列与原作者的文件相同,如果不同,那你就要手动修改 shp2clip 函数内的语句。并且下一次换用另一种 shapefile 文件时就又需要修改。
这里把白化部分的功能单独拿出来进行讲解:pcolor、pcolormesh、imshow、quiver 和 scatter 方法返回的对象都是 matplotlib.collections.Collection 的子类,可以直接用 set_clip_path 方法进行剪切;而 contour 和 contourf 返回的结果是每一级的等值线(用 PathCollection 表示)构成的列表,保存在 collections 属性中,所以需要迭代其成员进行剪切。代码中出现的 polygon_to_path 函数在前文有定义。
为了方便测试和复用代码,我写了一个 frykit 包,直接提供掩膜和白化相关的函数,并且加入了对坐标变换和填色图出界的处理(cartopy issue#2052)。另外 frykit 自带 ChinaAdminDivisonSHP 项目的 shapefile 文件,可以一行命令绘制中国国界、省界和市界,并且速度要比 add_geometries 快一些。更多说明请见 GitHub 页面,安装方法为
pip install frykit
依赖仅为 cartopy>=0.20.0。
下面以 2020 年 6 月 21 日 12 时(CST)的 ERA5 地表 2 米温度场和 10 米风场数据来演示
import numpy as np
import xarray as xr
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import cartopy.crs as ccrs
import frykit.plot as fplt
import frykit.shp as fshp
extents_map = [78, 128, 15, 55]
extents_data = [60, 150, 0, 60]
lonmin, lonmax, latmin, latmax = extents_data
# 读取并裁剪数据.
ds = xr.load_dataset('./data/ERA5/era5.tuv.20200621.nc')
ds = ds.sortby('latitude').sel(
time='2020-06-21 04:00',
longitude=slice(lonmin, lonmax),
latitude=slice(latmin, latmax)
)
t2m = ds.t2m.values
u10 = ds.u10.values
v10 = ds.v10.values
lon, lat = np.meshgrid(ds.longitude, ds.latitude)
# 开尔文转摄氏度.
ds['t2m'] -= 273.15
# 制作国界和省界的掩膜数组.
country = fshp.get_cnshp(level='国')
provinces = fshp.get_cnshp(level='省')
mask_country = fshp.polygon_to_mask(country, lon, lat)
masks_province = [
fshp.polygon_to_mask(province, lon, lat) for province in provinces
]
# 应用掩膜数组.
t2m_masked = np.where(mask_country, t2m, np.nan)
u10_masked = np.where(mask_country, u10, np.nan)
v10_masked = np.where(mask_country, v10, np.nan)
# 计算每个省的平均气温.
avgs = np.full(len(provinces), np.nan)
for i, mask_province in enumerate(masks_province):
if mask_province.any():
avgs[i] = t2m[mask_province].mean()
# 设置投影.
crs_map = ccrs.LambertConformal(
central_longitude=105, standard_parallels=(25, 47)
)
crs_data = ccrs.PlateCarree()
kwargs = {'projection': crs_map}
fig, axes = plt.subplots(1, 3, figsize=(12, 6), subplot_kw=kwargs)
fig.subplots_adjust(wspace=0.1)
for ax in axes.flat:
ax.set_extent(extents_map, crs_data)
# 准备cmap和norm.
cmap = plt.cm.plasma
vmin, vmax = -10, 35
norm = mcolors.Normalize(vmin, vmax)
levels = np.linspace(vmin, vmax, 10)
# 子图1绘制省平均气温.
ax = axes[0]
pc = fplt.add_polygons(
ax, provinces, crs=crs_data,
ec='k', lw=0.2, cmap=cmap, norm=norm, array=avgs
)
cbar = fig.colorbar(
pc, ax=ax, ticks=levels, orientation='horizontal',
pad=0.05, aspect=30, extend='both'
)
cbar.set_label('Temperature (℃)', fontsize='small')
cbar.ax.tick_params(labelsize='small')
ax.set_title('Averaged by Provinces', fontsize='medium')
# 子图2绘制掩膜后的气温场和风场.
ax = axes[1]
fplt.add_polygons(
ax, provinces, crs=crs_data,
fc='none', ec='k', lw=0.2, zorder=1.5
)
cf = ax.contourf(
lon, lat, t2m_masked, levels, cmap=cmap,
extend='both', transform=crs_data
)
cbar = fig.colorbar(
cf, ax=ax, ticks=levels, orientation='horizontal',
pad=0.05, aspect=30, extend='both'
)
cbar.set_label('Temperature (℃)', fontsize='small')
cbar.ax.tick_params(labelsize='small')
Q = ax.quiver(
lon, lat, u10_masked, v10_masked,
regrid_shape=25, transform=crs_data
)
patch_kwargs = {'linewidth': 0.5}
key_kwargs = {'labelsep': 0.05, 'fontproperties': {'size': 'x-small'}}
fplt.add_quiver_legend(Q, U=10, width=0.15, height=0.12, key_kwargs=key_kwargs)
ax.set_title('Masked by Country', fontsize='medium')
# 子图3绘制气温场和风场后再剪切.
ax = axes[2]
fplt.add_polygons(
ax, provinces, crs=crs_data,
fc='none', ec='k', lw=0.2, zorder=1.5
)
cf = ax.contourf(
lon, lat, t2m, levels, cmap=cmap,
extend='both', transform=crs_data
)
cbar = fig.colorbar(
cf, ax=ax, ticks=levels, orientation='horizontal',
pad=0.05, aspect=30, extend='both'
)
cbar.set_label('Temperature (℃)', fontsize='small')
cbar.ax.tick_params(labelsize='small')
Q = ax.quiver(
lon, lat, u10, v10,
regrid_shape=25, transform=crs_data
)
fplt.add_quiver_legend(Q, U=10, width=0.15, height=0.12, key_kwargs=key_kwargs)
fplt.clip_by_polygon(cf, country, crs=crs_data, fix=True)
fplt.clip_by_polygon(Q, country, crs=crs_data)
ax.set_title('Clipped by Country', fontsize='medium')
fig.savefig('applications.png', dpi=300, bbox_inches='tight')
plt.close(fig)
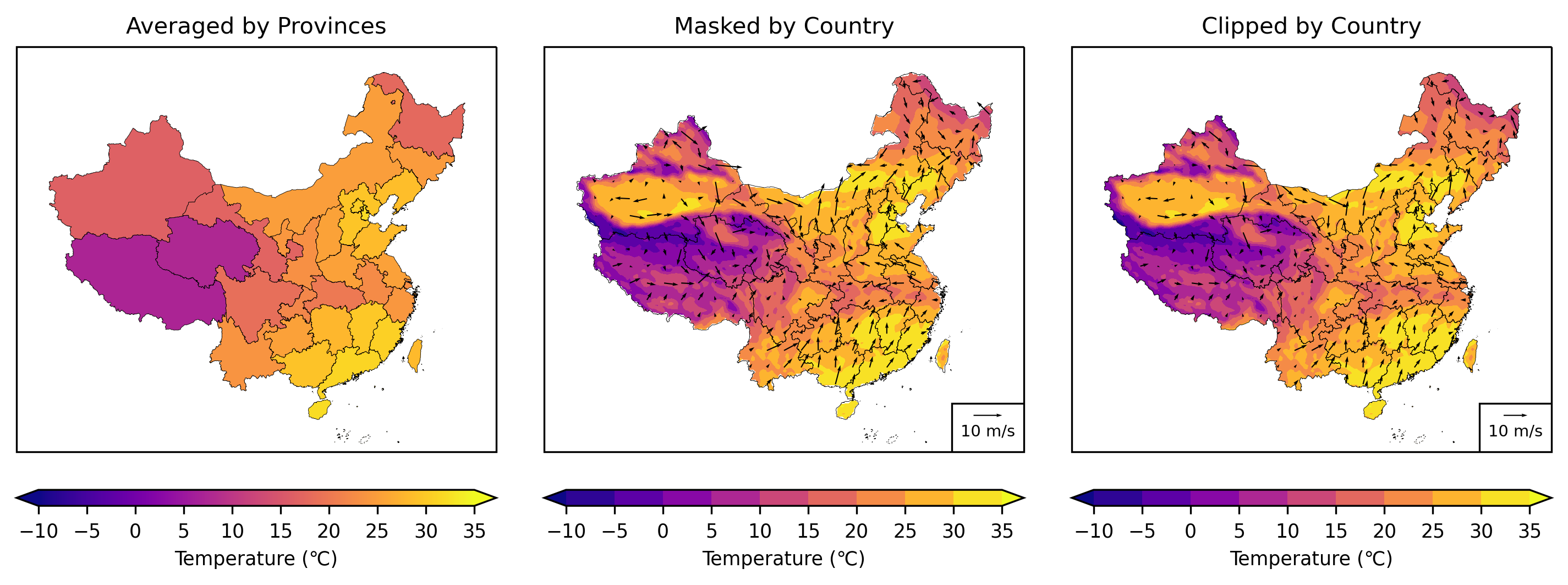
读者可以点击图片放大看看,第二张子图中填色图与国界间会有些参差不齐的空白,第三张子图中填色图则是严丝合缝地与国界贴在一起。
结语
本文稍微梳理了一下用 Matplotlib 和 Cartopy 绘制 shapefile 时所需的前置知识和工具链,虽然不了解这些也能用网上现成的代码完成简单的绘图,但只有理解了整个过程,才能使我们在设计复杂图形和 debug 时游刃有余(精美图像一例:Plotting continents… shapefiles and tif images with Cartopy)。当然对于赶时间的读者,我推荐使用 cnmaps 包,frykit 在很大程度上参考了 cnmaps 的 API。安装方法为
conda install -c conda-forge cnmaps
然后一行代码画国界、省界、市区县,也不用自己准备 shapefile
from cnmaps import get_adm_maps, draw_maps
draw_maps(get_adm_maps(level='国'))
draw_maps(get_adm_maps(level='省'))
draw_maps(get_adm_maps(level='市'))
同样一行代码白化填色图、伪彩图
from cnmaps import clip_pcolormesh_by_map, clip_pcolormesh_by_map
clip_contours_by_map(cs, map_polygon)
clip_pcolormesh_by_map(mesh, map_polygon)
另外还有直接导出 GeoDataFrame 等便利的功能,更多用法详见 cnmaps使用指南。本文内容较多,可能在一些地方存在错误,还请读者批评指正。另外如果本文中麻烦的 Python 操作可以用 ArcGIS 或 QGIS 等软件一键解决,也请多多介绍。
参考链接
A Python Protocol for Geospatial Data